


🔐 Private ChatGPT
Next — Today I Learnt About Data Science | Issue #85

Hi there!
Last week, I talked about fine-tuning large language models. To recall, there are three major ways:
Fine-tuning the base LLM model which improves its skills (akin to regurgitating a textbook before exam),
Retrieval-based learning which expands its extended knowledge base (akin to having an open-book exam),
In-context learning which expands its short-term memory (akin to having a cheatsheet).
Today, I will give an example of type-2 learning. This is likely the most common method that systems will be developed in future. It is the right balance between the knowledge gained by LLM and computation cost of learning. The third alternative is almost free but is also quite limited.
Last week, I was also quite frustrated with Spotify’s recommendation algorithm which played more recent songs more often than older songs from my library. I created an automated solution that might interest some music lovers.
Let’s dive in!
🔍 Retrieval-based Learning
I am not sure who coined the term “retrieval-based learning” in context of LLM-learning. I am pretty confident it was borrowed from psychology literature which found students who practiced retrieving from their memory what they learned performed better than students who didn’t. A few researchers from Google were probably the first to formally study its math, but you don’t need to understand how a car engine works to drive a car.
There are a few steps in making retrieval-based learning work. First, you need to have an embeddings generator that can encode all your knowledge into a some numbers. Second, the embeddings have to be stored in a safe format. It definitely cannot be CSV because of exploding file size. Parquet files seem to be the current standard. Third, you need to have a good searching algorithm for similarity — when a user asks a question, you need to know what parts of your extended knowledge are relevant.
Finally, once you found the relevant information, it has to be able to decode those embeddings back to raw information and communicate back to the LLM for generating the response. Of course, all of these steps have to be fast enough that the user can feel its magic.

🕸️ Embeddings
What are embeddings? It seems like I have used this term ten times without explaining its meaning.
My first project with image classification was with Pokemons. Given a pokemon’s image, can I identify their primary and secondary types? My approach was to convert the images to their pixel numbers and use them to make the prediction. If you’ve played with MNIST data, you likely know what I am talking about as well.
Similarly, when you work with textual data in Natural Language Processing, you convert the text to its tokens. The problem with token is that its sheer size. English has over six million words and if you represent every sentence with a bag of words, you will see most words are hardly used while words like “the” are often used. Additionally, you have no representation of meaning.
Using a more advanced model, you may use Word2Vec or Doc2Vec to create vector representations of the underlying knowledge. Essentially, this is what an embedding is.
An embedding is a relatively low-dimensional space into which you can translate high-dimensional vectors. Embeddings make it easier to do machine learning on large inputs like sparse vectors representing words. Ideally, an embedding captures some of the semantics of the input by placing semantically similar inputs close together in the embedding space. A good embedding can be learned and reused across models.
In addition to being small in size, embeddings also have much better results in searching. Since the numerical vectors now have a “meaning”, different models can search easily. In fact, it often doesn’t matter whether you use a powerful search method or simple cosine similarity, you get almost the same results.
Text is not the only information that can be converted to embeddings. Image embeddings can help with search. Audio embeddings can help with recommendations. Video embeddings can enable video search. It can help segment anything.
🛢️ VectorDB
Now that we understand how embeddings work, let’s take a look at the next link in the chain: vectorised databases. VectorDBs suddenly rose in popularity with LLMs. In fact, they are heavily funded right now.

They’re not (as) complicated. They are simply a tabular <key, value> pairs that store the embeddings that can be useful for information retrieval at a later stage. Of the ones above, I personally like Chroma most, because it is open-source and well documented.
🔭 Semantic Search
For semantic search, cosine similarity is the most popular method. The choice doesn’t matter much and cosine is probably the fastest to compute.
⛓️ Working Together
To this end, I have created several LLM retrieval engines for my personal use and research. In this Github repo, I have a minimal working example of such an information-retrieval chatbot. You can put whatever text documents you want in the documents folder in this chatbot and it will work seamlessly. See the readme file to learn more.
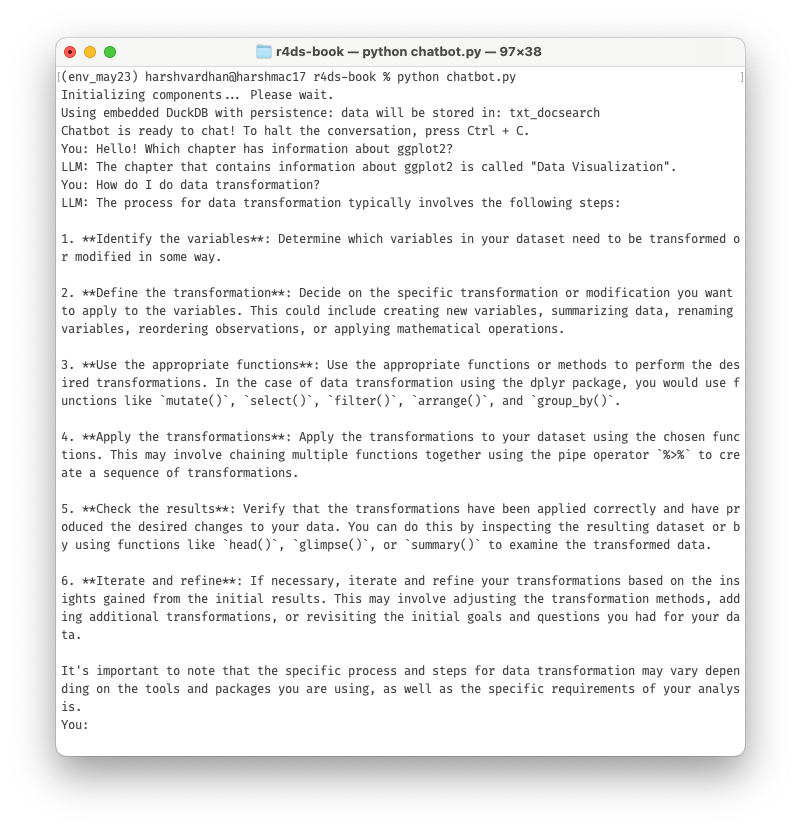
If you want to try it, here are the steps. They’re also in the repo’s readme in slightly more details.
Fork this Repository: Head over to this GitHub repo and fork it.
Clone Your Fork: `git clone https://github.com/your-username/r4ds-book-chatbot.git`
Install Dependencies: Run `pip install -r requirements.txt`
Documents: Put in your custom documents in the `documents` folder, unless you want to use R4DS as your training material.
Run the Bot: Navigate to the folder and run `python chatbot.py`
Enjoy! Just like that, you will have your own chatbot running the show. 🎭
If you run into issues, don’t hesitate to comment below.
See you next week!
— Harsh