


🇺🇸 US State-by-State Electricity Sources
Next — Today I Learnt About Data Science | Issue #79

Hi there!
Today, we explore a range of topics, including Facebook's CommutingZones project and its novel perspective on local economies, state-by-state visualizations of the U.S.'s electricity generation, the dynamic functionalities of the Papermill Python library, Python environment management explained through a unique hiking trip analogy, and New York's incredible linguistic diversity.
Read on!
Five Stories
Commuting Zones: Dataset
The CommutingZones repository on GitHub is a project by Facebook Incubator. Commuting zones are geographic areas where people live and work and are useful for understanding local economies, as well as how they differ from traditional boundaries.
Commuting zones are geographic areas where people live and work and are useful for understanding local economies, as well as how they differ from traditional boundaries. These zones are a set of boundary shapes built using aggregated estimates of home and work locations.
The data used to build commuting zones is aggregated and de-identified. The project is licensed under the MIT license. For more details, you can visit the project's GitHub page or its official website.
How does US generate its electricity? State-by-state Visualisations
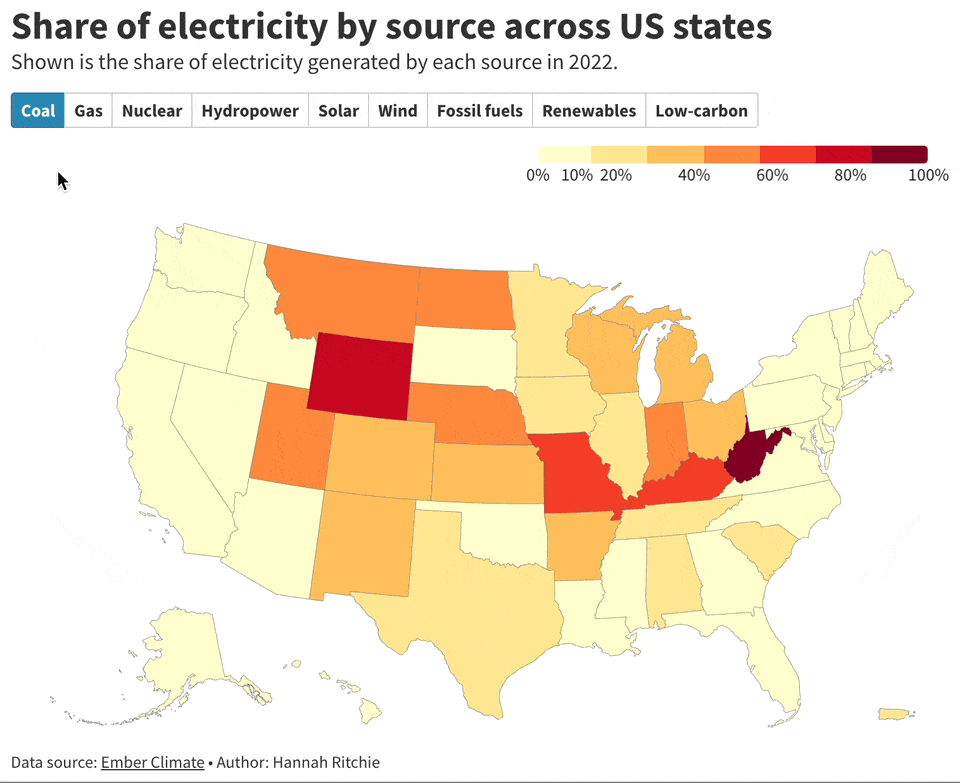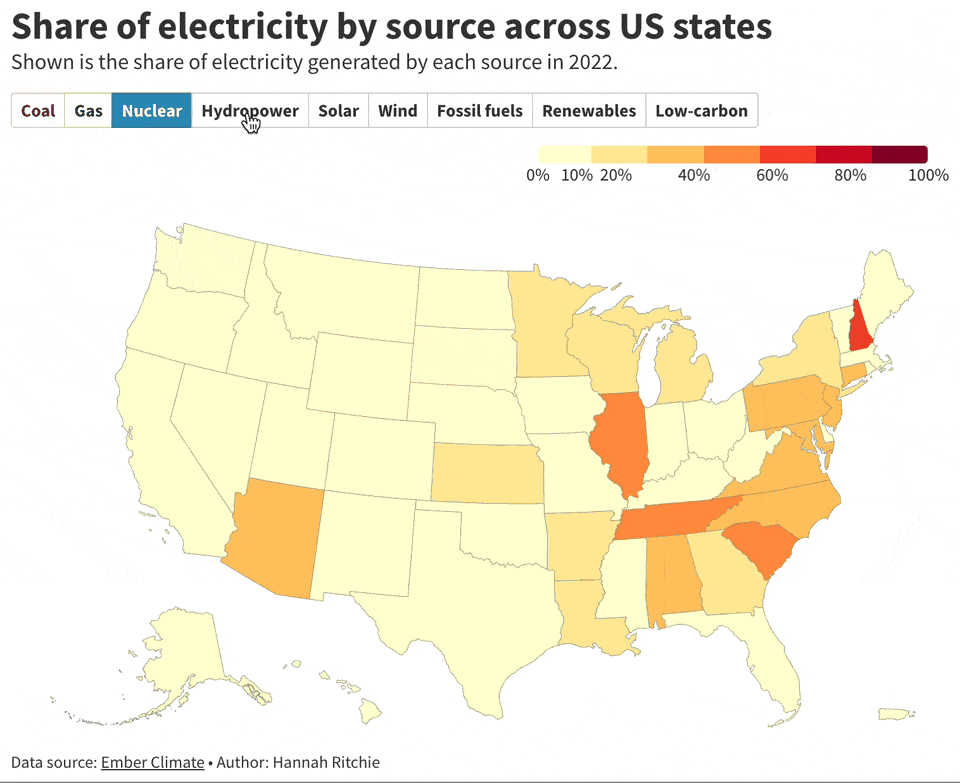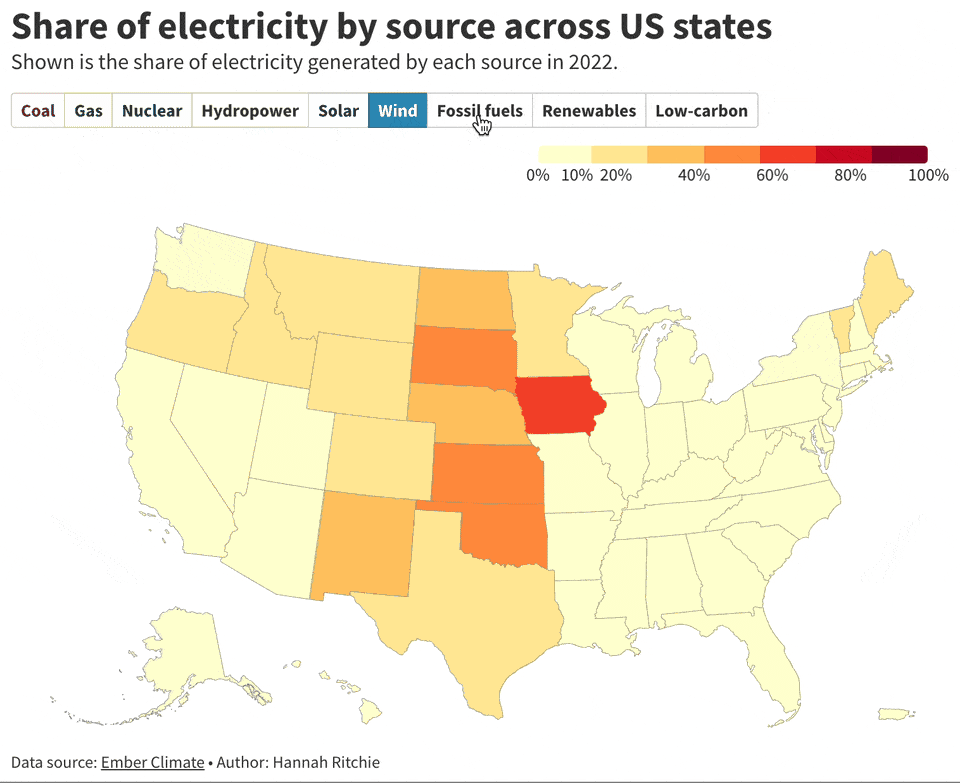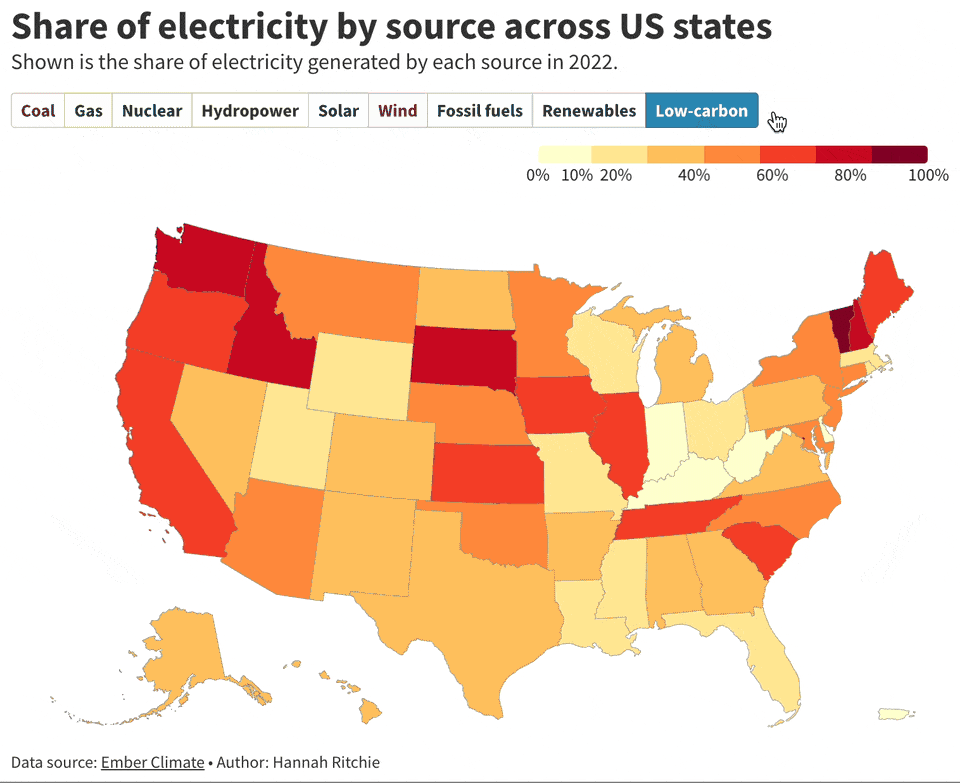
This captivating collection of visualizations by
showcases the diverse sources of electricity generation across U.S. states. West Virginia stands out, generating a staggering 89% of its electricity from coal, the highest in the nation. In contrast, New Hampshire leads in nuclear power, contributing to 58% of its electricity. Remarkably, Vermont has fully embraced low-carbon alternatives, generating 100% of its electricity through these sustainable methods.Batch Processing Jupyter Notebooks with Papermill
In this article, Matthew Long and Anderson Banihirwe, discuss the use of Papermill, a Python library to run and parametrize Jupyter notebooks. When you have a long process that could be a function, but should not be, parametrized notebooks are the solution.
Papermill is a solution to these issues. Use the tag of “parameters” — all that requires. The post provides a step-by-step guide on how to use it. It let’s you:
Summarize collections of notebooks
Execute and collect metrics across notebooks
Ease productionizing of notebooks
Transform your Jupyter notebook on a data workflow tool
Execute each cell sequentially, without having to open JupyterLab
Apply parameters to the source notebook, execute the notebook with the specified kernel, and save the output in the destination notebook
Understand Python Environment management through a hiking trip
The blog post titled "Understand Python Environment management through a hiking trip" by Jean-Marc Alkazzi uses an engaging hiking trip analogy to explain Python environment management. He compares Python programmers to adventurers, projects to trips, Python environments to backpacks, and Python libraries to tools.
The post covers the challenges we face in managing different libraries for different projects and introduces solutions like conda, pipenv, poetry, and virtualenv as 'assistants' that prepare the 'backpack' for each project. Full fun and really good.
Languages of New York
New York City, with speakers of about 10% of the world's languages, is the most linguistically diverse urban center in history. Despite the dominance of world languages like English and Spanish, the city is home to speakers of languages found almost nowhere else.
The Endangered Language Alliance, creator’s of the map, have worked with speakers of over 100 endangered and minority languages since 2010. The map pinpoints over 1200 sites linked to over 700 languages and dialects, providing a snapshot of the city's linguistic diversity.
Four Packages
Papermill: Papermill is a tool that enhances the utility of Jupyter Notebooks by enabling parameterization and execution. It facilitates tasks like running reports with varying values and executing workflows based on previous results, eliminating manual copy-pasting between notebooks. Github.
Bokeh: Bokeh is a powerful library for creating interactive plots and dashboards. It's great for visualizing large and real-time datasets in a way that allows users to interact with the data. Github.
Beautiful Soup: This library is used for web scraping purposes to pull the data out of HTML and XML files. It creates a parse tree from page source code that can be used to extract data in a hierarchical and more readable manner. Vignette.
Scrapy: Scrapy is an open-source and collaborative web crawling framework for Python. It's used for extracting the data you need from websites, and it's particularly useful for large-scale web scraping projects. Github.
Three Jargons
XGBoost (Extreme Gradient Boosting): XGBoost is a decision-tree-based ensemble machine learning algorithm that uses a gradient boosting framework. It's known for its execution speed and model performance.
LightGBM: LightGBM, short for Light Gradient Boosting Machine, is another tree-based learning algorithm that's part of the Microsoft Distributed Machine Learning Toolkit. It's designed to be distributed and efficient with the following advantages: faster training speed and higher efficiency, lower memory usage, better accuracy, and support for parallel and GPU learning.
AdaBoost (Adaptive Boosting): AdaBoost is a boosting algorithm which constructs a classifier. As you might know, boosting is an ensemble technique in which the predictors are not made independently, but sequentially. This technique employs the logic in which the subsequent predictors learn from the mistakes of the previous predictors.
Two Tweets

https://twitter.com/mdancho84/status/1678745203945906176
https://twitter.com/posit_pbc/status/1633589176615710720
One Meme

— Harsh