


What happened in the last two months?
Next #65 | Rewind Repeat Edition

Hi there!
Its been two months since I started publishing via Substack. Substack has allowed me a wider audience and it’s a lot easier to use. In today’s letter, I will highlight five stories, four packages and three jargons from the past eight letters. As per the custom, this edition will be called Rewind Repeat. Let’s jump in!
Five Stories
Stories on AI
I covered many stories on ChatGPT, generative AI and AI in general. Here are some cool ones:
I wonder how this AI thing is going to shape up, Harshvardhan
What is ChatGPT doing… and Why Does It Work?, Stephen Wolfram
How Duolingo’s AI Learns What You Need to Learn, Duolingo Team
What should you use ChatGPT for?, Vicky Boykis
Why the super rich are inevitable?
The Pudding
In a classic Pudding scroll, we learn how some individuals end up as super rich by pure chance. This is true with no taxes and higher taxes can prevent it… to an extent.
The Yard-sale model, developed by physicist Anirban Chakraborti, is a simulation that shows how uneven trades can lead to a concentration of wealth in the hands of a few people. Physicists got involved in studying inequality through the field of econophysics, where they applied their methods to economics. The Yard-sale model demonstrates that government intervention and taxation can help redistribute wealth and prevent a single person from accumulating all the wealth.
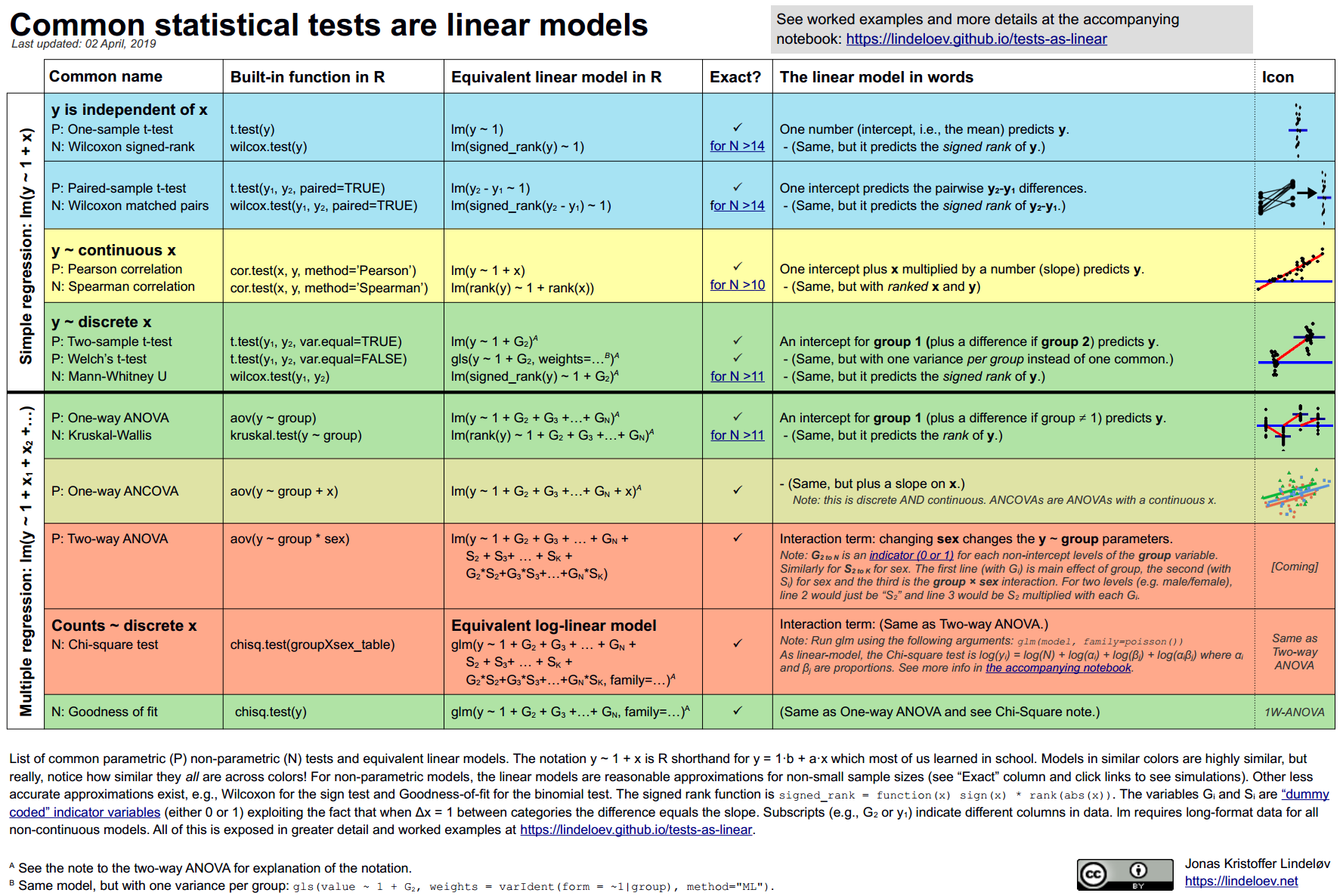
Common statistical tests are linear models
Jonas Kristoffer Lindeløv
Most statistical tests can be reformulated as linear models. I “discovered” this sometime around second year of my undergraduate and asked my professor why didn’t anyone tell me I could fit a linear regression model and arrive at the same conclusion!
Hidden Patterns in Albanian Street Names
Dea Bardhoshi
Part 1: Dea explored the gender distribution of street names in Tirana, Albania, using data from OpenStreetMap and hand-labelling (hats off for the effort!). The author found that only 3.3% of the street names were named after women, and most of them were foreign women. She also used natural language processing techniques to analyze the most common words and topics in the street names and found that they reflected the history and culture of Albania.
Part 2: In the follow up piece, she discovers who are these people who get this privilege. The biggest group seems to be politicians, writers and fighters. (These are based on manual labelling by her; kudos for industrious effort.) Which politicians? Late 19th and early 20th century. Communist politicians are the fourth biggest category.
Discovering and learning everything there is to know about R packages using r-universe
Jeroen Ooms
r-universe is a new umbrella project by rOpenSci under which they experiment with various ideas for improving publication and discovery of research software in R. The project aims to help you effectively navigate the R ecosystem to discover what is out there, get a sense of the purpose and quality of individual packages, their developers, and get started using packages immediately and without any hassle.
The project also shows a shuffling list of organizations that publish R packages (sorted by recent activity) which is a fun way to discover what is currently being developed in the R ecosystem. The search homepage is fun to play around.
Four Packages
MakeItTalk is a Python package developed by Adobe that converts a picture to an audio-led animated video. Marlene Mhangami showed us an example!
datapasta aims to make copying and pasting data to and from R easier by providing add-ins and functions that support a wide range of input and output situations, reducing the need for intermediate programs like Sublime or MS-Excel. Vignette.
generativeart can create wonderful art based on mathematical formulations. Check it’s Github to see what it can do.
streamlit lets you convert Python data scripts into sharable web apps. I’ve been desperately looking for Shiny alternatives in Python and maybe this is it! Github.
Three Jargons
Hallucinations in AI learning refer to when an AI system generates or outputs data or information that is not based on reality, but rather on the patterns and associations it has learned from the training data.
For example, an image recognition system trained on a dataset of dogs might generate an image of a "dog" that has multiple heads or legs, simply because it has learned that the presence of certain features (e.g. fur, ears) are strongly associated with the label "dog" in its training data, without understanding what a real dog actually looks like.
In some cases, these hallucinations can be harmless or even amusing, but in other cases they can have serious consequences, such as when an autonomous vehicle "sees" a non-existent object and causes an accident, or when a chatbot generates offensive or harmful responses based on its training data.
Self-attention is an ML technique that helps a model understand the relationships between different elements in a sequence. It helps the model determine which words in a sentence are most important for determining their meanings. The model does this by assigning weights to each word, indicating how much attention should be paid to it.
A generative model is a type of machine learning model that is designed to generate new data that is similar to the training data it was trained on. Unlike discriminative models that are used to classify input data into different categories or labels, generative models try to learn the underlying distribution of the data and generate new samples that follow that distribution.
Two Tweets


One Meme

Bonus
Opinionated Guides to Engineering, Music, Design, Philosophy. The interview section is pretty cool!